

Qu’est-ce que l’Open Data ?
L’Open Data est un concept qui décrit la liberté d’utilisation des données, puisque chacun peut les utiliser, les partager, les redistribuer ou les republier. Les données doivent être légalement ouvertes, publiées dans le domaine public pour être utilisées avec un minimum de restrictions, et techniquement ouvertes, car elles doivent être publiées dans des formats techniques ouverts disponibles au téléchargement.
La licence Open Data est utilisée pour établir la base juridique de l’utilisation des données publiées. Les données ouvertes doivent faire l’objet d’une licence. Sa licence doit permettre aux personnes d’utiliser les données librement, y compris la transformation, la redistribution, la republication et même à des fins commerciales.
Choisir une licence Open Data
- Creative Commons : CC-By et CC0 (Public Domain Dedication)
- Open Database License/Open Data Commons Open Database License
- (ODbL) Open Data Commons Public Domain Dedication and Licence (PDDL),
Certaines organisations gouvernementales et internationales ont publié leur propre licence Open Data comme la Worldbank Data License , la French open Data License , et la UK Gov. Data License .
Qu’est-ce qu’un portail de données ouvert ?
La solution de portail de données est un logiciel web conçu pour publier des ensembles de données, il est souvent utilisé par le gouvernement pour publier des ensembles de données afin de fournir une transparence à ses citoyens. Le portail de données permet à l’organisation de publier ses données, de les organiser, de les étiqueter/classer en catégories, et est souvent accompagné d’outils de gestion des données avec des outils de reporting et de visualisation des données comme des cartes, des graphiques.
Open source vs commercial
Les solutions open source sont souvent accompagnées d’un plus grand nombre de modules, d’une intégration d’applications et d’une utilisation à grande échelle, car elles regroupent également une puissante communauté d’utilisateurs comprenant des développeurs expérimentés qui participent parfois à la production et au développement d’extensions et de plugins.
Portails de données open source
1-CKAN

CKAN est un portail de données open source conçu pour permettre la publication, le partage et la gestion d’ensembles de données. Il offre de nombreuses fonctionnalités aux gestionnaires et aux utilisateurs finaux comme la recherche plein texte, un support multilingue, des outils de reporting et une puissante API pour accéder aux données.
CKAN offre de nombreuses options pour les spécialistes des données, notamment des rapports et des options géospatiales pour publier et partager des données géoréférencées. CKAN peut être étendu grâce à des plugins.
CKAN est la star des portails de données car il est le choix le plus populaire des gouvernements et des ONG pour publier/partager leurs ensembles de données.
2-DKAN

DKAN est un portail de données open source très similaire à CKAN bien qu’il soit doté de fonctionnalités plus orientées vers les données, notamment le scrapping, la collecte de données, le flux de données visuel, des options de visualisation avancées, un CMS/ blog intégré pour publier des articles/ billets, ce qui le rend très puissant pour le référencement.
DKAN est basé sur le CMS Drupal, le CMS open source basé sur PHP, ce qui le rend un peu différent, en termes d’installation et de gestion de CKAN qui est basé sur Python/PostgreSQL.
Les utilisateurs de DKAN sont principalement des organisations gouvernementales et des ONG.
3-Socrata

Socrata est un serveur de données open source pour la publication/gestion d’ensembles de données. Il propose un ensemble d’outils puissants de gestion des données, notamment la gestion de bases de données, des outils de manipulation des données, des outils de reporting, la visualisation avec des options avancées et des aperçus d’analyse financière personnalisés.
Scorata dispose 2 licences : une licence open source pour l’édition communautaire et une licence commerciale pour l’édition entreprise.
Scorata a été utilisé par certains États américains comme l’Oregon et plusieurs autres États.
4- Dataverse

Dataverse Solution de dépôt de données open source conçue pour partager/gérer de grands ensembles de données. Il aide ses utilisateurs à collecter, organiser et publier leurs données sur une plateforme collaborative.
Dataverse compte plus de 40 installations dans le monde entier, y compris des ONG, des organisations gouvernementales et des centres de recherche.
5- Swirrl

Swirrl est une application web open source auto-hébergée pour la publication de données, comprenant une structure collaborative qui permet à de nombreux utilisateurs de contribuer à l’établissement de rapports, à l’organisation, à l’analyse et à la publication des données.
Les fonctionnalités de Swirrl comprennent la publication de données géolocalisées, la recherche plein texte, un outil de manipulation, de conversion et de fusion de données, ainsi qu’une interface utilisateur simple qui facilite la gestion et améliore l’expérience de l’utilisateur. Swirrl dispose d’une API conviviale pour les développeurs qui permet aux utilisateurs d’accéder aux données et de les intégrer dans leurs rapports/applications.
Bien que Swirrl ait été conçu à l’origine pour un usage gouvernemental, il a été choisi par de nombreux centres de recherche dans le monde entier. et le NHS ( National Health Services – Royaume-Uni).
6- The DataTank
DataTank est un projet open source destiné aux développeurs car il fournit un système entièrement fonctionnel pour convertir des ensembles de données en une RESTful-API fonctionnelle.
Le DataTank prend en charge plusieurs formats de données dans des fichiers de texte brut comme les fichiers JSON, CSV, RDF, XLS, JSON-LD, SHP avec un entrepôt de données MySQL.
7- GeoServer

GeoServer est un serveur open source pour le partage de données géospatiales. GeoServer utilise des outils cartographiques open source OpenLayers pour publier des rapports interactifs sur les ensembles de données géospatiales.
GeoServer est utilisé par plusieurs institutions et par une large communauté de développeurs. De bons manuels ont été publiés pour installer, gérer et maîtriser les GeoServers, ce qui permet à ses nouveaux utilisateurs de s’épanouir et d’enrichir la communauté.
8- Soda

Soda est une distribution Drupal open source légère conçue pour collecter, gérer et distribuer des données ouvertes (à petite échelle). Soda est publié sous licence GPLv3.0. Elle est facile à installer et à gérer. Comme Soda est construit sur Drupal, il hérite de la plupart de ses fonctionnalités en tant que CMS, ce qui le rend flexible en tant que système de gestion de contenu (CMS) entièrement personnalisable.
9- Truedat

Truedat est un cms de publication de données open source, construit pour fournir une interface personnalisable pour gérer, publier des données avec des fonctionnalités de reporting avancées. Truedat est conçu pour être convivial pour les concepteurs et les développeurs, car il offre une mise en page entièrement personnalisable.
Les caractéristiques de Truedat comprennent le balisage/la classification, le reporting des données, la personnalisation du front-end, des outils prêts pour le référencement, le contrôle qualité, le suivi du flux de données, le dictionnaire de données et l’administration des utilisateurs.
10- Magda
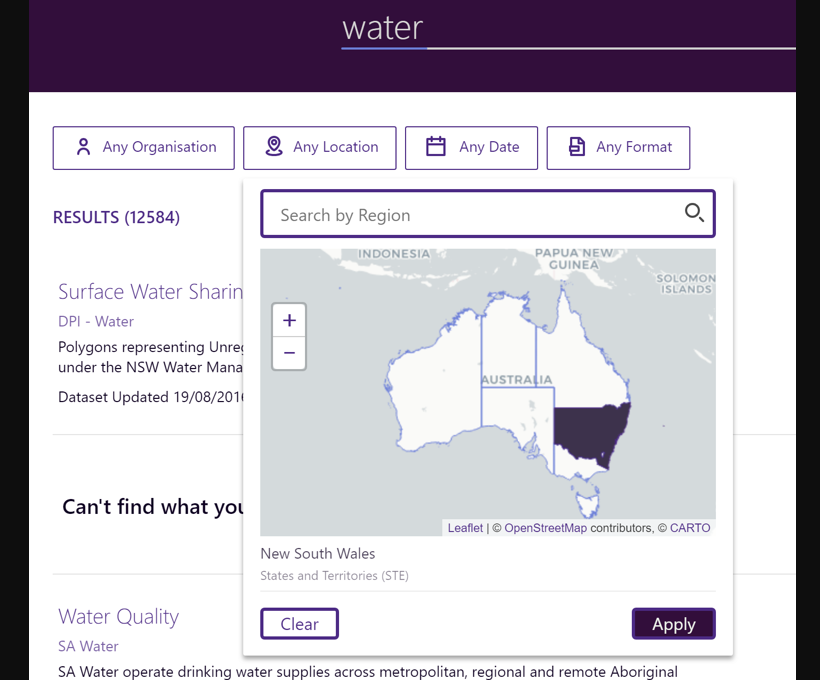
Magda est un projet open source qui aide les développeurs/utilisateurs expérimentés à construire un écosystème de données. Le projet a commencé comme agrégateur de données mais a évolué pour permettre la publication, la gestion et le partage des ensembles de données.
Magda dispose d’une fonction de recherche avancée puissante qui prend en charge la recherche plein texte, comprend les synonymes et les acronymes, et est également dotée de filtres puissants avancés. Il est livré avec une puissante API riche qui permet de l’utiliser facilement avec des projets externes.
Magda est construit sur une architecture modulaire qui permet aux développeurs de créer leurs propres extensions et d’ajouter de nouvelles fonctionnalités. Vous pouvez voir Magda en action sur le portail de données du gouvernement australien. Magda est encore en cours de développement intensif, alors n’oubliez pas de suivre le projet pour les prochaines versions.
Magda utilise de micro-services (minion) pour surveiller les changements/mises à jour des données et effectuer une certaine opération en cas de changement.
11- JKAN

JKAN est un portail de données léger et open source construit sur un générateur de site statique « Jekyll ». Son backend est totalement libre, ce qui le rend léger et également limité en ce qui concerne les fonctionnalités requises par les bases de données.
JKAN peut être installé comme Jekyll sous forme de pages statiques, même dans des pages Github. Il possède de nombreux thèmes et un développeur expérimenté peut créer des thèmes pour lui avec facilité. JKAN est très facile à installer, à configurer, à gérer et à mettre à jour, ce qui le rend plus préférable que les solutions lourdes en termes de backend.
JKAN est utilisé pour le portail estonien de données ouvertes, Sandiego gov Data Portal.
12- GeoNode: CMS Geospatial Data

GeoNode est un CMS pour les jeux de données géospatiales, qui permet à l’utilisateur de publier des jeux de données géospatiales avec de puissantes options de visualisation, des fonctionnalités de recherche avancées, de créer des cartes interactives et de collaborer avec d’autres utilisateurs. GeoNode est également une plate-forme puissante pour les développeurs qui souhaitent développer des systèmes d’information géospatiale (SIG) et déployer des infrastructures de données spatiales (IDS). Le CMS GeoNode est construit avec Django, et il fonctionne très bien avec les projets basés sur Django.
13- Hue: Construire des portails de données via SQL

Hue n’est pas un portail de données, c’est un outil de développement pour construire des applications de données basées sur des bases de données SQL. Hue est essentiellement un éditeur et un assistant pour SQL qui aide les développeurs à visualiser, construire leurs applications et portails de données en utilisant des ensembles de données enregistrés dans des bases de données SQL. Hue supporte de multiples sources, y compris Apache Hive, Apache Impala, Apache Presto, les bases de données SQL list MySQL, PostgreSQL, Oracle, BigQuery, en fait n’importe quelle base de données basée sur SQL.
Hue dispose d’un catalogue puissant qui comprend des options de recherche et de marquage ainsi que des outils visuels qui permettent à l’utilisateur de naviguer, de rechercher, de marquer, d’importer ou de fusionner les données. Hue est livré avec des fonctions de visualisation avancées intégrées dans son tableau de bord. L’une des fonctions les plus utiles qui permettra à l’utilisateur de gagner du temps est la création de flux de travail, la planification et l’automatisation.
14- Open Data Node (ODN)
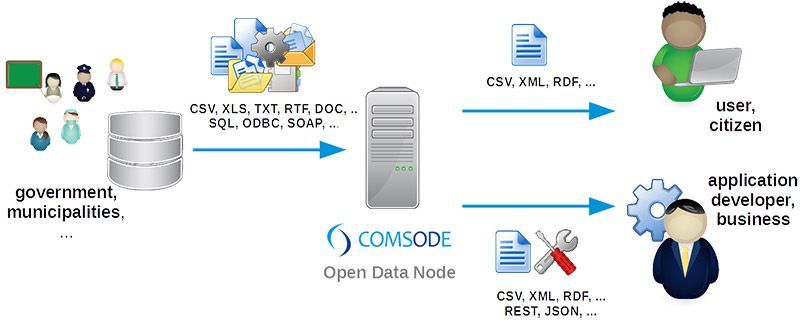
Open Data Node (ODN) est une plateforme de publication de données ouvertes, qui s’intègre bien avec d’autres portails de données ouvertes comme CKAN et Socrata. L’Open Data Node est doté de fonctions automatisées qui facilitent la publication, la découverte et la manipulation des données pour les utilisateurs/développeurs.
Open Data Node (ODN) fournit des utilitaires permettant aux développeurs de créer leurs applications à partir des données publiées.
15 – Open Data Catalog

Open Data Catalog est un portail de données/ CMS open source construit à l’origine comme un portail de données pour OpenDataPhilly.org de Philadelphie. Il est construit avec Django et utilise la base de données PostgreSQL.
16- Open Geoportal (OGP) (JAVA)

Open Geo portal est une application web à source ouverte permettant de publier et de partager des données géographiques. Open Geoportal est publié sous licence GPL v3 et construit avec Java.
17- Data Fair
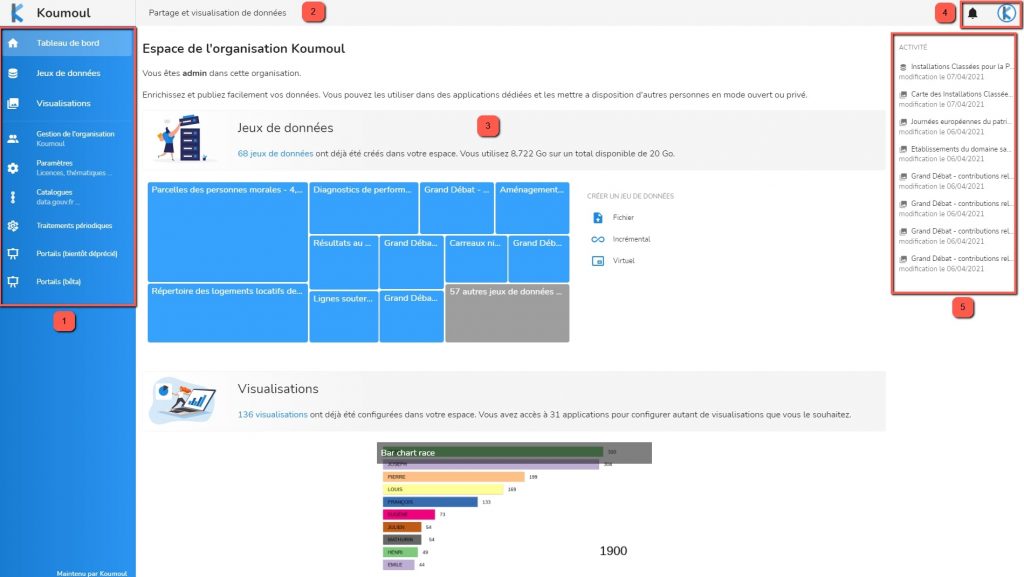
Data Fair et son écosystème permettent de mettre en œuvre une plateforme de partage (interne ou opendata) et de visualisation de données. Cette plateforme peut être à destination du grand public, qui peut accéder aux données au travers de visualisations interactives adaptées, aussi bien qu’à un public plus expert qui peut accéder aux données au travers des APIs.
Le mot FAIR fait référence à de la donnée « Facile à trouver, Accessible, Interopérable et Réutilisable ».
2 commentaires
Bonjour,
Merci pour cet article récapitulatif.
Nous éditons également une solution de portail de données en open source (AGPL 3). Cette solution s’appelle Data Fair : https://data-fair.github.io/2/ et est par exemple utilisée par l’ADEME : https://data.ademe.fr/.
Si vous souhaitez compléter votre article, je suis à votre disposition pour en discuter ou vous fournir des éléments d’information.
Bien cordialement
I will